
Let’s take a quick dive into Kafka storage system and see what it entails. In the end, it is hoped that this short article unravels and simplifies Kafka file system and motivates someone to work more pragmatically with Kafka. We shouldn’t treat Kafka clusters as black boxes.
Storage Fundamentals
Let’s say we have a topic named, login-events with 3 partitions on a single node cluster and a producer using default partitioner publishing messages to the cluster. To clarify quickly,
- Default Partitioner uses the algorithm, “
hash(key) % Number of Partitions” to determine which partition each message will be written to by its key. - It means that messages of the same key will always be written to the same partition unless the number of partitions in a topic is changed.
- For sake of understanding, we have hypothetically used integer message keys in the diagram to simplify hash-code computation as the
hash(int) = int.

Besides the meta and auxiliary file types which will be explained later, a Kafka cluster contains the following hierarchical data model/structure;
Topic: A category or feed name used to logically organize messages. It is divided into a number of partitions for better throughput, storage efficiency and scalability.
Partition: The basic unit of storage and parallelism. In a multi-node cluster, a partition can’t be shared between brokers but can be replicated to more than one broker. Each partition is broken into one or more files called segments.
Segment: A segment is an append-only physical data file that is filled sequentially with messages and their offsets. The essence of breaking each otherwise large partition into smaller segment files is to make purging of stale messages more workable with minimal overhead and cost. A segment can either be active or inactive. An active segment is the one that is currently being written to by the producer and can’t be purged or cleaned. An inactive segment is any closed segment that is eligible for deletion or compaction. A segment name is fixed-length (20 digits long) and is always the base-offset, the offset of the first message in the segment padded with trailing zeros. A segment age is the timestamp of its newest message.
Kafka File System Overview
Each Broker has one or more data directories specified in the server.properties file. After a short period of producer activity, the Kafka broker data directory (specified by log.dirs property) usually looks like this.
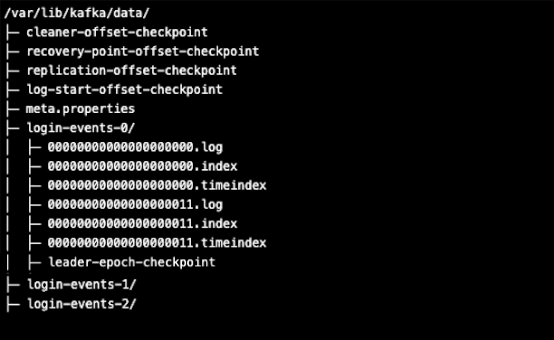
The subdirectories, “login-events-0“, “login-events-1“, “login-events-2” represent the 3 topic partitions. Each partition directory contains one or more segment, index and meta files. Let’s briefly explain the purposes of root files shown.
- cleaner-offset-checkpoint: Where Kafka checkpoints the last cleaned offset of all topic partitions. It is used to compute the dirtyRatio of inactive segments prior to log compaction. The file format is <topic-name> <partition number> <offset>
- recovery-point-offset-checkpoint: Where Kafka tracks which messages (from-to offset) were successfully flushed to disk for each topic partition.
- replication-offset-checkpoint: Where Kafka tracks which messages (from-to offset) were successfully replicated to other brokers for each topic partition. It’s like an offset high water mark of the last committed, replicated message.
- log-start-offset-checkpoint: Where Kafka tracks the first/earliest offset of each topic partition.
- meta.properties: Where Kafka checkpoints the latest cluster and broker metadata like clusterId and brokerId.
Besides “meta.properties”, the format of the other 4 files is;
1st line contains the version
2nd line contains the number of line entries to follow
each line has <topic-name> <partition number> <offset>
Partition Directory Overview
Indexes: The index files are used for retrieving messages by offset or timestamp. There are three index files.
- “.index” suffix file maps offsets to their byte positions in the associated segment file
- “.timeindex” suffix file is a time-based index file that uses the message timestamp to transverse a segment file. It shares same name as the log segment.
- “.txnindex” suffix file is only created if a transactional producer is publishing to a topic partition. It stores the latest state of a transaction and not the actual messages in the transaction. The transaction could be in various states like “Ongoing,” “Prepare commit,” “Prepare abort”, “Completed”, “Aborted”. The “read_committed” consumers cache it so that they can skip aborted transactional messages (i.e. those messages which are in the log but don’t have a transaction marker associated with them).
Idempotent Producer Snapshot: “.snapshot” suffix file is only created if an idempotent producer is publishing to a topic partition. It maps the unique producerID, PID to a message sequence number. It shares same name as the log segment, the base-offset which is the offset of the first message in the associated segment file.
Leader Epoch Checkpoint: Designated as “leader-epoch-checkpoint” file on each partition, it is where Kafka checkpoints the latest recorded leader epoch and the leader’s latest offset upon becoming leader. Each row is a checkpoint containing two columns namely, the epoch and the offset by definition.
Others include “.deleted”, “.cleaned” and “.swap” suffix files that are used by the log cleaner to purge and swap log and index files.