
Let’s quickly examine how data is transmitted in and out of a Kafka pipeline between the producers, brokers and consumers.
Typically, when compression is properly configured and enabled on the producers, messages are published compressed, stored compressed on the brokers, fetched compressed and then finally decompressed by the consumers.

Produce Vs Fetch Request
Compression Flow
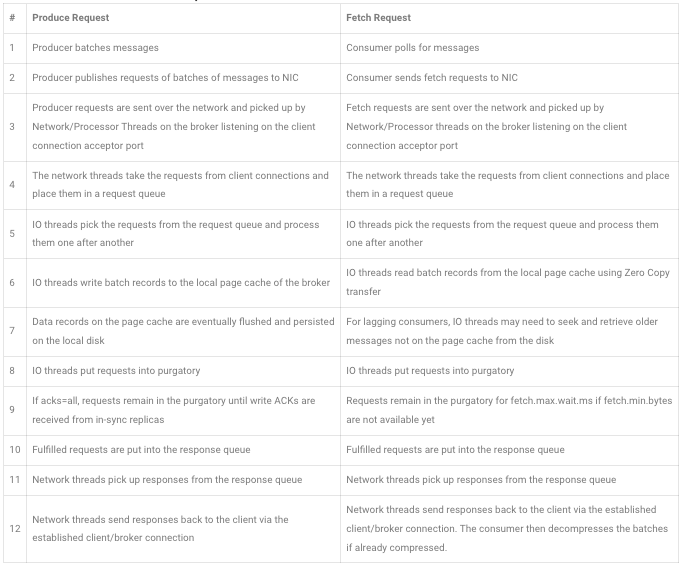
If producer compression was enabled on a pipeline, a typical request/response dataflow would be as indicated below using markers in the diagram above.
- The producer batches and compresses messages: 1
- The producer publishes compressed batches of messages: 2
- The broker receives compressed batches: 3, 4
- The broker processes and stores the batches compresssed: 5, 6, 7, 8
- The broker serves and sends compressed batches to consumer : 10,11,12, 2
- The consumer decompresses the fetched batches: 1
Avoid Compression Anti-Pattern/Misconfiguration

The use of appropriate compression algorithm in data pipelines cannot be over-emphasized in order to save cost on disk storage and reduce the risk of network saturation, especially in situation where there is a limited, often expensive dedicated connection bandwidth between the client network like on-prem data-center and Kafka cluster on the cloud.
Whereas either the producers or the brokers could be configured to perform compression, consumer would inevitably have to carry out decompression.
Common challenge and issue with enabling compression is how to avoid unnecessary and unsolicited compression and decompression cost. Typical anti-pattern use cases include:
- Double compression on both the producers and the brokers: Shown as 1 and 4 above and may happen when the cluster
compression.typeis not consistent with that of the producers or is not set to “producer” in order to retain the original compression codec set by the producers. - Unintended broker decompression: Shown as 1 and 5 above and may happen when the cluster
compression.typeis inadvertently set touncompressedwhile the majority of the producers are setup with their preferredcompression.type.
Ideally, you want to set your choicest compression.type on the producers which often have spare, easily scalable CPU cycles rather than on the Kafka cluster. Besides that, the compression type of the topics being published to and that of the Kafka cluster must be set to “producer” or same as that of the producers. Luckily enough, the compression.type = producer on Brokers and Topics by default.
Another compression evil is with older consumers (0.10.0 and lower), where down conversion becomes more expensive when compression is enabled and used on their data pipelines. This is because, for the oldest message format version 0 supported by these old Kafka client versions, the brokers always decompress the messages to assign incremental individual offsets to inner messages. So, if majority of the consumers are running 0.10.0 and lower, you may experience high CPU spikes on the brokers and overall performance degradation.
Lastly, don’t rely on the default values for batch.size, linger.ms, buffer.memory when enabling producer compression. Tweak them for better compression ratio as most compression codecs perform optimally with large batches because of intrinsic repetition between messages of the same type.