
Kafka supports two cleanup policies which can be specified either cluster-wide “log.cleanup.policy” or topic-level override “cleanup.policy” configuration as a comma separated list of any of these values:
delete: Log Retention (how long or how much of a data you want to store)
compact: Log Compaction (where you need to only store the latest value of each key)
Both delete and compact can be specified together. This could be ideal for use cases where many keys potentially go stale and never updated again and taking up disk space. So, make sure you understand the behaviour and performance characteristics of your data pipelines before using this combined policy.
In most data platforms, the Kafka data retention strategy is often a decision for both the business and data architects and should be planned because of its cost implication, data integration and dependency concerns between upstream and downstream systems, and data compliance checks and regulations like GDPR.
Log Compaction
Log compaction is a native Kafka retention mechanism that retains the latest value for each key.

Use cases
- To reload and restore application state after a crash or system failure from a changelog
- Database change capture
- Journaling for high-availability e.g. group-by like and aggregation operations
Configuring Log Compaction
Log compaction can be enabled for a topic via a topic-level configuration override, “cleanup.policy”. The equivalent of this configuration at the broker level is “log.cleanup.policy”. Below is the list of other useful log compaction configurations.
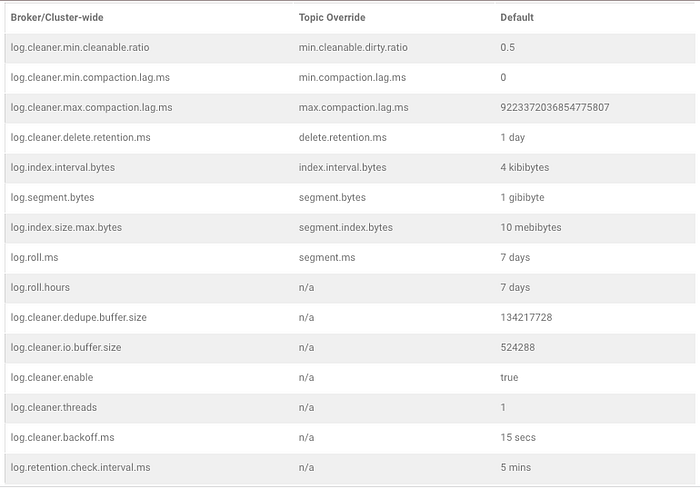
How Log Compaction works
The compaction algorithm itself is not that complicated but can be very volatile and easily forgotten. So, I decided to go visual and depict it diagrammatically rather than provide a written illustration. I hope readers will better retain their knowledge of log compaction and also use the flowchart for future reference and illustration.
In light of this, the flowchart has been annotated with relevant broker configuration settings and where appropriate with the corresponding topic level configurations. You should always override the topic-level configuration settings in most cases unless you have a justifiable reason to make cluster-wide changes that will impact all topics.
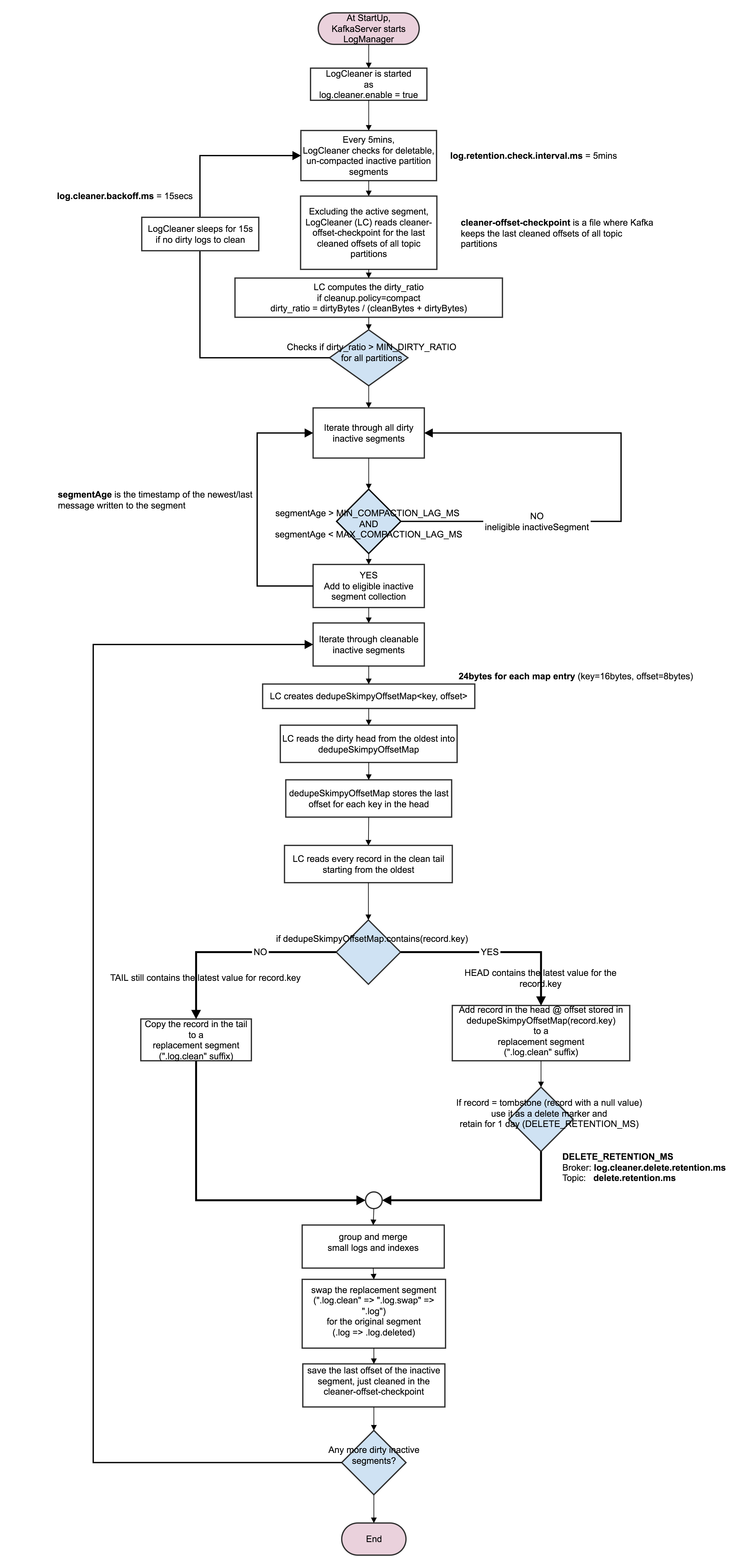
Segment View of a Partition Log
Important considerations
- Consider tweaking the topic-level configurations,
segment.msand/orsegment.bytesif you are seeing stale messages that should have been deleted or duplicate, uncompacted records. Your producer throughput is probably low to fill up the current active segment quickly enough (default size: 1 GB) to roll it into inactive segment for log retention and compaction to kick in. - Consider using a smaller,
min.cleanable.dirty.ratioas a hint to the Log cleaner thread to make segments with less dirty head eligible to compaction sooner. Although this has the potential of saving storage, log cleaner may not keep up as it cleans the dirtiest inactive segments first. - Consider setting a topic’s
min.compaction.lag.ms(default value: 0) to guarantee for a minimum time period to pass after the newest message has been written to segments before they can be compacted. This would be useful if you wanted to retain messages long enough for consumers to see them before they are subject to compaction - Although not a hard guarantee, consider setting a topic’s
max.compaction.lag.msto a desirable value to ensure any inactive segment is eligible for compaction within a maximum time frame since it was last written to. This can be used to prevent log with low produce rate from remaining ineligible for compaction for an unlimited period as depicted by this configuration default value (9223372036854775807). Depending on the available cluster resources and performance, Kafka will attempt to comply to this threshold on best effort. - Consider changing the default value of
delete.retention.ms(1 day) to give more allowance for offline or intermittent consumers to read tombstone records when they are finally live and connected to the cluster and do handle them accordingly to consistently update their backends or downstream dependencies.